Machine Learning のチュートリアル:
Azure Machine Learning Studio で初めてのデータ サイエンス実験を作成する
・・・をやってみる。。。。
https://docs.microsoft.com/ja-jp/azure/machine-learning/machine-learning-create-experiment#step-1-get-data
まず、
https://studio.azureml.net
に入る。here Sgin in
実験用のサンプルデータをDL、workspaceへ。
左下の [+新規] をクリックして新しい実験を作成し、[EXPERIMENT (実験)] を選択してから [Blank Experiment (空の実験)] を選択・・・
実験の名前をわかりやすい名前に変更
「20170815_price_prospect」へ。
サンプルデータをドラッグ入力。
(図1)
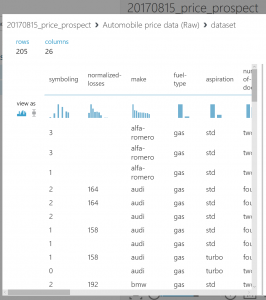
visualizationで一応データ確認
(図2)
データを準備ーーー
値が不足している場合には、これらの不足値をクリーニング(=除く)する必要があります。。。。と。
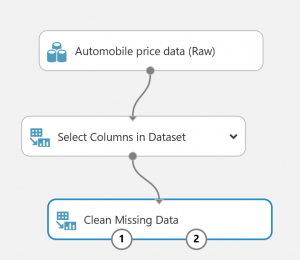
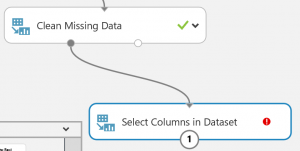
「select column in dataset」を選択モジュールから見つけて、実験キャンバスにドラッグ・・
(図3)
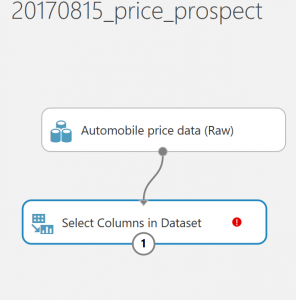
データセットの出力ポートを、データセット内の列の選択モジュールの入力ポートに接続
(図4)
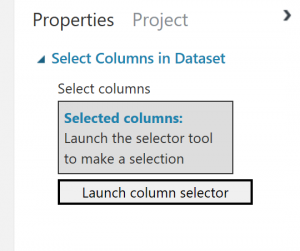
[プロパティ] ウィンドウの [Launch column selector (列セレクターの起動)] をクリック
(図5)
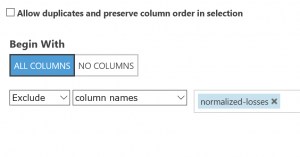
列セレクターの起動と “normalized-losses” 列の除外”
(図6)
見つからないデータのクリーンアップ モジュールを実験キャンバスにドラッグして、データセット内の列の選択モジュールに接続。
[Cleaning mode (クリーニング モード)] の下の [Remove entire row (行全体を削除)] を選択。
(図7)
ページの下部の [実行] をクリックして、実験を実行。
右上隅にも [実行が完了しました] というステータスが表示。
(でも、ここまで実験で実行したことは、データのクリーンアップのみです、、、と。)
特徴を定義するーーー
データセット内の列の選択モジュールを、実験キャンバスにドラッグ。
見つからないデータのクリーンアップ モジュールの左側の出力ポートを、データセット内の列の選択モジュールの入力に接続。
(図8)
学習アルゴリズムを選択して、適用するーーーー
データの分割モジュールを選択して実験キャンバスにドラッグし、最後のデータセット内の列の選択モジュールに接続。
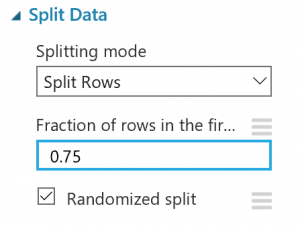
データの分割モジュールをクリックして選択。
プロパティを 0.75 に設定します。
このようにして、データの 75% をモデルのトレーニングに使用し、25% をテスト用に保持しておきます
(図9)
モデルのトレーニング モジュールを見つけて、実験にドラッグ。
線形回帰モジュールの出力を、モデルのトレーニング モジュールの左側の入力に接続。
次に、データの分割モジュールのトレーニング データ出力 (左側のポート) を、
モデルのトレーニング モジュールの右側の入力に接続
モデルのトレーニング モジュールを選択して、[プロパティ] ウィンドウの [起動列セレクター] をクリックし、
[価格] 列を選択します。 これが、作成しているモデルで予測する値です。
新しい自動車の価格を予測ーーーー
これまでにデータの 75% を使用してモデルをトレーニングしました。
ここからは残りの 25% のデータにスコアを付け、モデルの機能の効果を確認します。
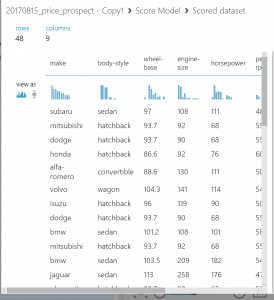
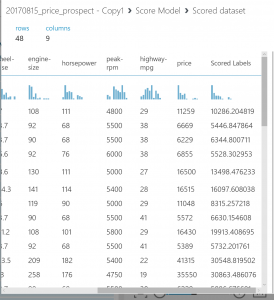
実験を実行して、モデルのスコア付けモジュールの出力を表示します
(モデルのスコア付けの出力ポートをクリックして、[視覚化] を選択します)。
出力に、予測された価格の値と、テスト データから既知の値が表示されます。
(図10)
(図11)
モデルの評価モジュールの出力を表示するには、出力ポートをクリックして、[視覚化] を選択します
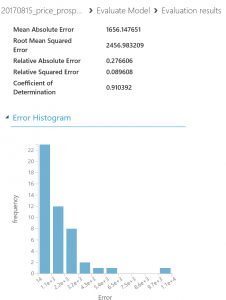
(図12)
平均絶対誤差 (MAE): 絶対誤差の平均 ( 誤差 とは、予測された値と実際の値との差)。
二乗平均平方根誤差 (RMSE): テスト データセットに対して実行した予測の二乗誤差平均の平方根。
相対絶対誤差: 実際の値とすべての実際の値の平均との絶対差を基準にした絶対誤差の平均。
相対二乗誤差: 実際の値とすべての実際の値の平均との二乗差を基準にした二乗誤差の平均。
決定係数: R-2 乗値ともいいます。どの程度モデルが高い精度でデータと適合するかを示す統計指標。
画像は、以下にまとめて・・・・